|
I graduated with an MS in Computer Sciences from University of Wisconsin-Madison (UW-Madison) in May 2021, where I worked on Storage Systems (Key-Value Stores) and Machine Learning for Systems (Learned Indexes) under Prof. Remzi and Andrea Arpaci-Dusseau.
Email / Resume / Github / LinkedIn / Other links |
 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
|
|
|
|
|

|
Sandboxing of untrusted language procedures within RDS PostgreSQL
|
|
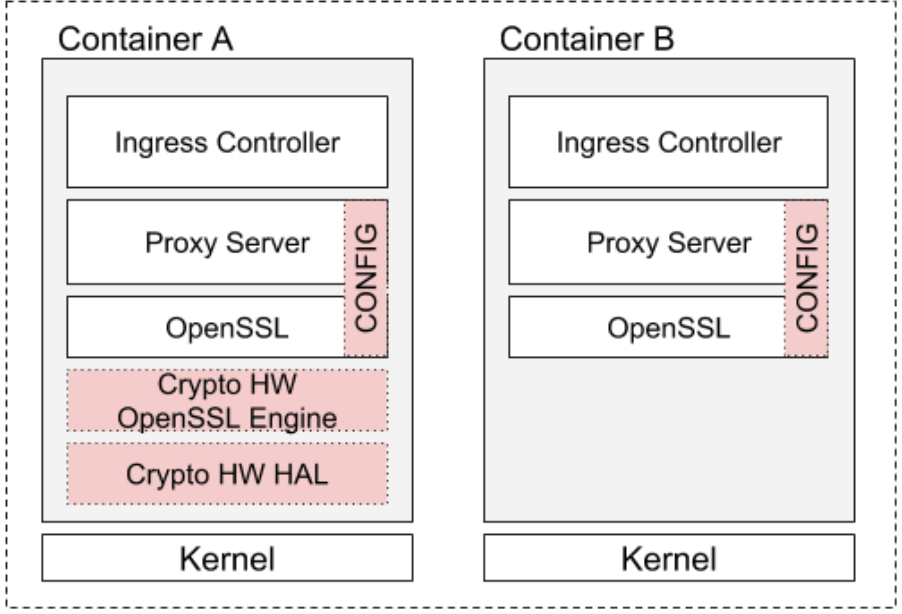
Hardware Acceleration of Proxies
|

|
Characteristics-Tailored Summary Generation
|

|
Domain-specific Customer Care Chatbot
|
|
|
|

|
Recently, research efforts have gained pace to cater to varied user preferences while generating text summaries. While there have been attempts to incorporate a few handpicked characteristics such as length or entities, a holistic view around these preferences is missing and crucial insights on why certain characteristics should be incorporated in a specific manner are absent. With this objective, we provide a categorization around these characteristics relevant to the task of text summarization: one, focusing on what content needs to be generated and second, focusing on the stylistic aspects of the output summaries. We use our insights to provide guidelines on appropriate methods to incorporate various classes characteristics in sequence-to-sequence summarization framework. Our experiments with incorporating topics, readability and simplicity indicate the viability of the proposed prescriptions.
|
|
|
|
|
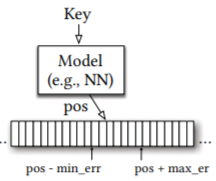
Log-Structured Merge (LSM) based key-value stores have become so popular today that they are used as backend for NewSQL database abstractions like TiDB. They use indexes for faster data lookup whose memory overhead increases with database size leaving lesser memory for caching data blocks. We employ learned techniques to reduce this space overhead without compromising read latencies. We also explore learning approaches to prioritize compactions and devise new compaction policies
|
|
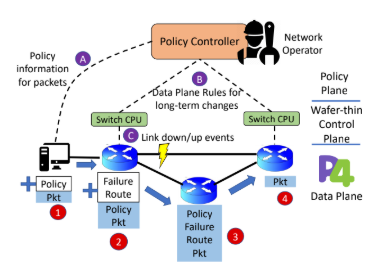
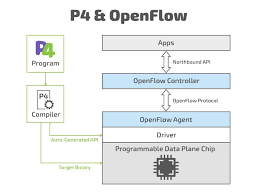
On failures, routers typically have inconsistent state, which leads to high convergence times. In such cases, the central software controller could be a bottleneck and finding policy-compliant paths is hard. We propose for computation of such paths in the data plane with a central policy plane across end-host interfaces
|
|
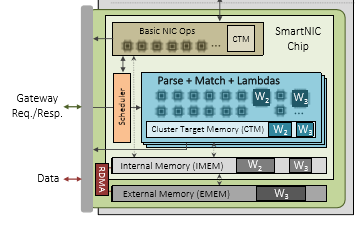
Typical traffic trace dumps from network simulators, or mathematical simulations of network topologies with variation in queuing, sending rates, etc can aid in online learning of weights in an effort to load-balance traffic across several outgoing links. We explored such approaches utilizing SmartNIC / P4 switch computations
|
|
The project aims at replicating locally stored states in the primary switch to the secondary switch in real-time to avoid loss of state information in case of failures. Locally stored states aid in packet processing at line rate
|
|
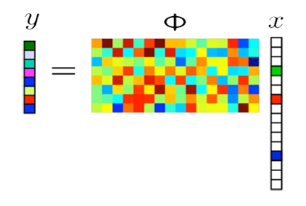
Typical Raman spectroscopy takes a very long acquisition time and is used for diagnosing critical diseases like cancer. The aim of this project is to reduce the acquisition time without compromising on quality
|
|
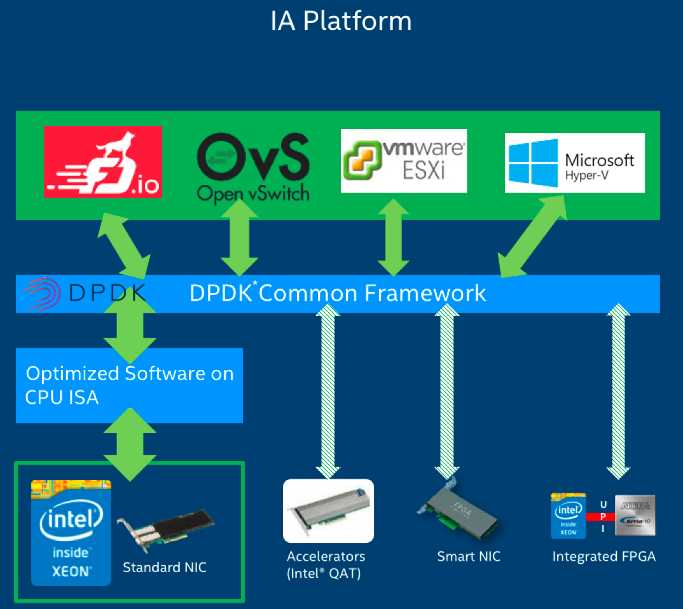
VPP and Open vSwitch are currently the fastest DPDK-based software switches out there. The aim was to determine the minimal resources required for optimal performance of a switch for different use cases
|
|
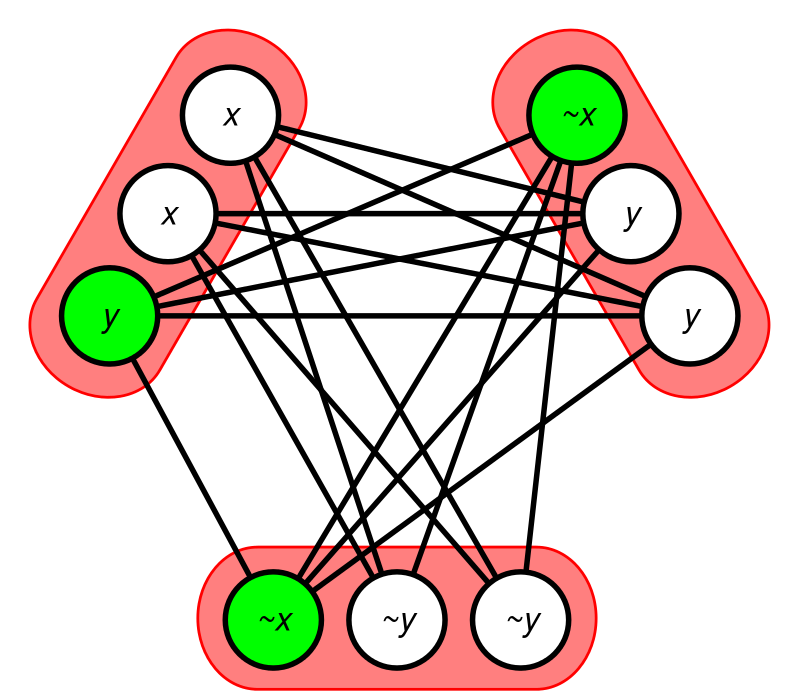
The task involved a study of different model-counting algorithms, which enumerate solutions to a boolean formula. The aim was to identify performance bottlenecks in the implemented model for optimization
|
|
|
|
|
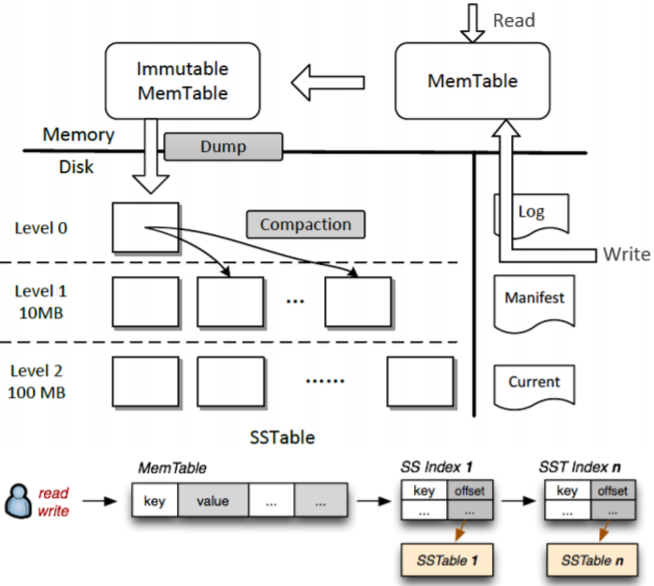
Modern database systems leverage key-value stores based on Log-Structured Merge (LSM) trees for storing metadata requiring fast lookups and updates. However, recent studies show that application throughput can be compromised by internal LSM tree operations that periodically write data to disk. The existing background work scheduler on Google's LevelDB was improvised for better application performance. Runtime parameters like memtable and SSTable sizes, triggers for compaction and stalling writes were auto-tuned using a Bayesian Optimizer, MLOS to adapt to various workloads. The foreground writes were decoupled from background memtable flushes and compactions and showed 2.24-2.34X improvement for industrial write bursty workloads in terms of observed client write throughput by scheduling these background operations during idle periods or when there were very few or no writes to the database
|
|
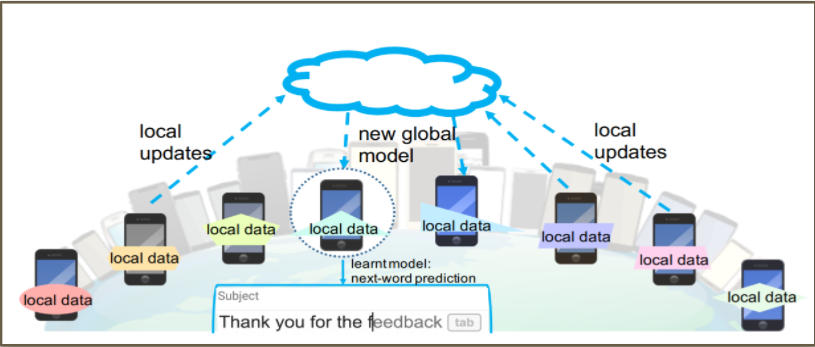
Federated learning entails training statistical models directly over numerous remote devices using local data leveraging their storage and computation capabilities. Security and data privacy concerns have pushed computation to the edge in contrast to classic ML training over centralized servers within datacenters. Centralized approaches like Parameter Server, Elastic Averaging SGD are compared with variants of Decentralized-PSGD. Biased and unbiased gradient compression operators like top-K, random-K, quantization via ECD-PSGD, DCD-PSGD and ChocoSGD are explored, with communication-computation overlap via Asynchronous D-PSGD to reduce idle time using bounded stale gradients. Training statistical efficiency is observed over time for bits transmitted across topologies like torus, ring with Stochastic Gradient Push (SGP) for directed graphs. Decentralized SGD algorithms with compressive communication are on par in convergence guarantees with their centralized counterparts
|
|
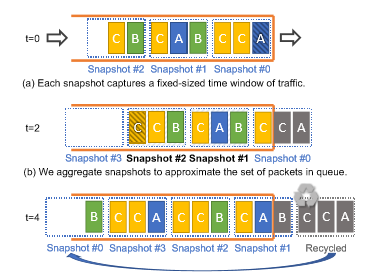
Recent active queue length management algorithms like RED, ECN, CoDel probe queue length to throttle sending rate across all senders. However, they do not aim to identify contributing flows as the root cause of queue build-up. Here, I explored Count-Min Sketches which overcome scalability issues of per-flow counters and dynamic allocation issues of hashmaps to accurately record per-flow queue occupancy. Distributed across snapshots comprising a fixed number of packets (alternately, of specified time intervals), each snapshot utilizes a count-min sketch based on register arrays in P4 to track flows in that interval, while cleverly reusing them after a certain total packet count. I tested my implementation on mininet with ECN-based feedback notifications to senders, thus utilizing Flow Completion time as a metric to demonstrate the effectiveness of this approach. I also used a C++ simulator with Pcapplusplus on UW Data Center Measurement Trace to evaluate Precision and Recall of the "contributing flow" classifier
|
|
Image segmentation is used in medical imaging for tumour detection and edge detection for tracing blood capillaries and roadside kerbs for autonomous driving. Here, we try to accelerate the algorithms using CUDA, leveraging GPU and hybrid OpenMP+MPI approaches, leveraging multicores. We demonstrate optimizations like SIMD, loop unrolling, use of templates, forced inlining along with use of shared and unified memory, while exposing need for constructs like atomic/critical sections and thread synchronization/barriers through the implementation of Sobel & Canny edge-detectors and the Fuzzy C-Means algorithm for segmentation. Our work focuses on using CUDA streams, dynamic parallelism and thrust library along with OMP tasks to achieve high speedup
|
|
We designed a utility-based agent based on genetic algorithms, using a set of 10 state-dependent features like numer of holes, height differences between adjacent columns, max height of a column, etc. We used the single-point crossing over heuristic and implemented a multithreaded training approach random independent block sequences in parallel. Particle swarm optimization was also employed along with this for optimal convergence of weights to add an exploratory component. We achieved a maximum of over 856,000 cleared rows. Additionally, we implemented an auto-encoder approach with Q-learning for a low dimensional game state representation. Though not quite successful with Tetris, we demonstrated a simple game "Catch the Ball" with the above approach to demonstrate its effectiveness |
|
We designed a freetext search engine supporting both phrasal and boolean queries, leveraging NLTK to retrieve and rank legal case judgments. We finished 2nd out of 33 teams on the leaderboard based on the assignment given by the Singapore-based legal intelligence firm, Intellex. Positional indices were implemented to aid proximity search with additional zone and field indices like court hierarchy, legal case dates to aid in retrieval. We were able to get a high F1 score using various query expansion techniques like pseudo relevance feedback using the Rochhio algorithm, WordNet synonyms and co-occurence thesaurus generated from the corpus dictionary. We used the LNC model of tf-idf for freetext search |

|
I implemented normalized graphcuts with α-expansion for image segmentation and denoising using multilabel 8-connected Markov Random Fields, and compared the same with mean-shift algorithm. I employed the PatchMatch algorithm to establish patch correspondences, for better alignment for homography. The other component involved obtaining dense correspondences from two images belonging to different viewpoints using manual methods and KLT tracker, to estimate the Fundamental Matrix using the 8-point algorithm |
|
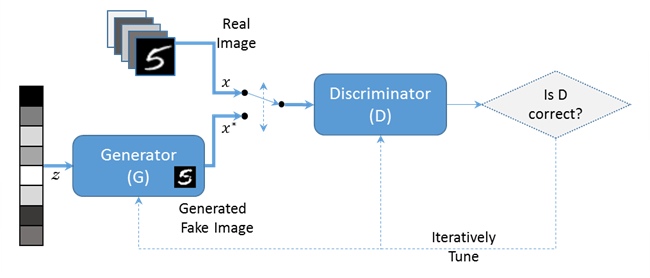
We built a Deep Convolutional GAN model on pytorch for generating new game levels, i.e. tile sheets from previous game layouts. We used Leaky ReLU as the activation function for both the discriminator and generator with the Adam Optimizer for stochastic gradient descent |
|
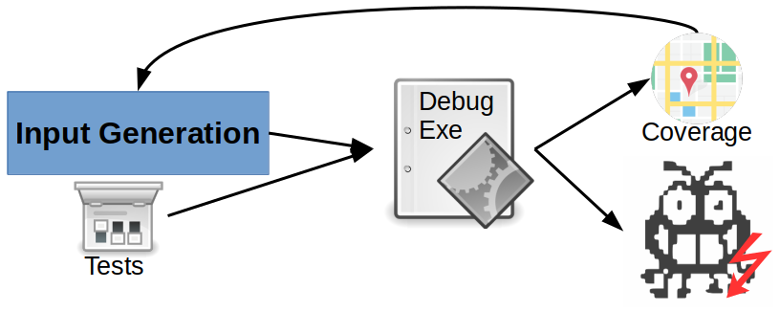
We made a comparison of general-purpose mutation-based grey-box fuzzers like libFuzzer, American Fuzzy Lop (AFL) and honggfuzz and evaluated their performance on the Google fuzzer-test-suite across 24 applications on metrics like code coverage (basic blocks and edges) and bug-finding capabilities. We found a new unreported bug in pcre2-10.0 with the key finding that only libFuzzer can find memory leaks with the help of LeakSanitizer. Also proposed a new framework for ensemble fuzzing which uses different base fuzzers in tandem
|
|
Explored the Probabilistic Programming Monad in Figaro, which combines the object-oriented paradigm with the functional programming paradigm in Scala. Modeled real-life problems using Bayesian Networks with inference algorithms like Variable Elimination, Belief Propagation and Dynamic Reasoning algorithms like Factored Frontier. Simulated a simple market model using Decision Models to calculate the optimal policy. Extended the language by implementing a new Element class to model the distribution of the maximum value of a random variable, sampled from 0 to a given upper bound |

|
We employed the Efros & Leung algorithm to synthesize larger textures, and used the same algorithm with a modified cost function for iterative texture transfer to target images using correspondence maps. We also implemented the minimal error boundary cut using dynamic programming to avoid block-seam artifacts |
|
|
|
|
|
|
|
|
|
|
|
|
Contextual Marketing for Retail Analytics
|
|
|
Automated Timetable Generation
|
|
|
|
|
Designed an abstract syntax tree comprising unary and binary operations, conditionals, functions, recursive functions, applications and let constructs on various data types for the compiler, utilizing the Gram parser for parsing instructions. Implemented a virtual machine instruction interpreter with an operand stack for control flow. Performed type-checking using Hindley Milner type inference with support for optional data types. The compiler was further optimized to leverage tail recursion and contiguous stack frames |
Dynamic rendering techniques were used to create this animation film, based on OpenGL's various timer functions. Different camera transformations were used like dolly zoom to add artistic effects. I used motion simulation along Bezier curves, adding soft shadows and transparency effects using Ray tracing. For object modeling, Phong illumination and Phong shading were used with texture mapping and bump mapping to mimic real-life surfaces |
|
We built a multiplayer Pokemon game on PostgreSQL backend with JDBC API from pokeAPI JSON data with over 14,000 tuples. Online gym battles, navigable maps with probability models for capturing wild pokemon and evolution of pokemon with battle experience were also added
|
Developed an integrated Android and Django based web app for displaying submission deadlines, exam dates and other important reminders via push-notifications. Implemented automatic sync and signup with social logins, with security measures against XSS, CSRF etc
|
|
Developed an Ethernet-enabled FPGA module on VHDL to dispense cash leveraging greedy algorithm in Xilinx ISE, with Tiny Encryption algorithm to provide secure exchange of user data. Enforced insufficient balance, incorrect pin using LED displays, and frontend caching to protect against server crashes |
A server-client model with X11 based GUI was developed using Socket programming, with LDAP Authentication using openLDAP. Additional functionality for group chats, offline inbox via hashmaps and multimedia message exchanges were also supported
|
|
Designed a python program for generating correlation between the user and critic rating based on Euclidean distances. Using the critic ratings, generated a list of recommended movies for the user sorted according to ratings weighted by Pearson correlation coefficient calculated using similarity between user and critic's rating |
Designed and simulated a Rube Goldberg Machine using Box2D, a physics simulation engine in C++, which involves compilation and linking to libraries like GLUI (GLUT based C++ user interface library). Designed a Star Wars arena by rendering attraction, repulsion among magnetic objects |
|
Built a GUI based solver on MIT Scheme with features like Undo, Auto-solve, and filters for seeding games of varying difficulty levels. Employed backtracking algorithm to solve any given initial configuration
|
Built a class for enumeration of characters, words with support for Find and Replace using Knuth Morris Pratt algorithm, regular expressions, LZW compression and encryption and decryption via Caesar cipher |
|
Estimated body fat mass using stepwise regression with statistical tests to check for multicollinearity, lack of fit, outliers and influential points derived from cook's distance, dffits, dfbetas, studentised residuals implemented in R. The same was validated with partial F-test for the significance of model and Durbin-Watson test with Kolmogorov-Smirnov test for testing the independence and normality of residuals
|
Performed a critical study and simulation of the Random Excursions test and the famous sampling algorithm, Metropolis Hastings Algorithm
|